Self-Nomination for Decentralized CSI Feedback Reduction in MU-MIMO
A short overview of our TWC 2026 paper, Self-Nomination: Deep Learning for Decentralized CSI Feedback Reduction in MU-MIMO Systems.
In MU-MIMO systems, UEs typically report CSI regardless of how likely they are to be scheduled. This is natural from a system design perspective, but it can be quite inefficient. As the number of users grows, always-on CSI feedback creates unnecessary uplink overhead, extra UE-side power consumption, and more complexity in BS-side scheduling and precoding. A more direct question is whether each UE can learn, from its own channel, whether its CSI is actually worth feeding back.
Core idea
Each UE observes its own downlink channel vector $\mathbf{h}_k \in \mathbb{C}^{N}$ and makes a binary feedback decision
\[f(\mathbf{h}_k; \Theta) \in \{0,1\}.\]If $f(\mathbf{h}_k; \Theta)=1$, the UE nominates itself and feeds back CSI. Otherwise, it stays silent. Let $\mathcal{K}$ denote the set of self-nominated UEs. The BS then schedules up to $M$ users from $\mathcal{K}$ and performs precoding. In this work, we mainly consider ZF precoding after UE selection.
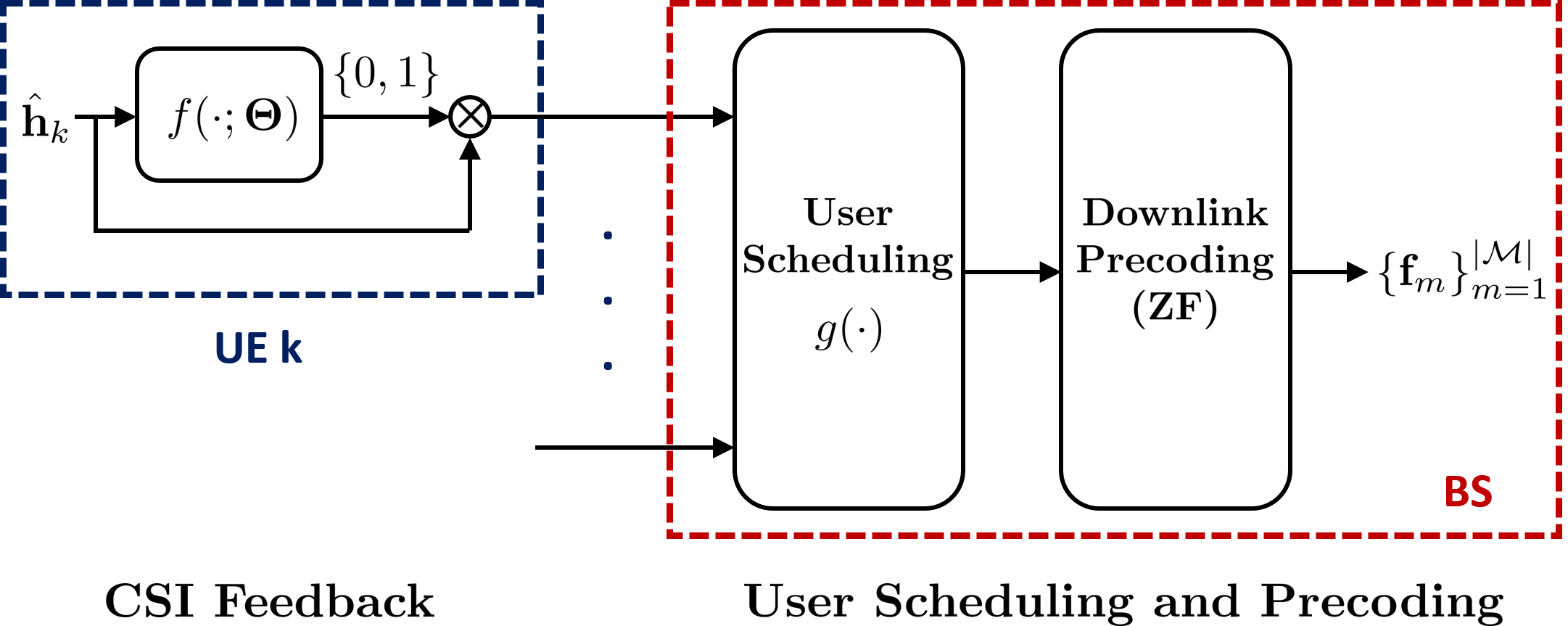
Self-nomination lets each UE decide whether to feed back CSI before BS-side scheduling and precoding.
We formulate the design under an average sum feedback constraint:
\[\max_{f(\cdot;\Theta)} \; \mathbb{E}\!\left[\sum_{m\in\mathcal{M}} w_m R_m\right] \qquad \text{subject to} \qquad \mathbb{E}\!\left[\sum_{k\in\bar{\mathcal{K}}} f(\mathbf{h}_k;\Theta)\right] \le N_{\mathrm{FB}}.\]So CSI feedback is no longer treated as something every UE should always send. Instead, it becomes a constrained decision problem.
Self-nominating DNN
The proposed self-nomination network maps each UE’s local CSI to a binary feedback decision. In the full-CSI case, the network sees the full channel vector, so it can use not only channel strength but also spatial structure. This is important in MU-MIMO, where good scheduling depends on more than just strong channels.
A key point is that the decision is made locally at each UE, but the policy is trained centrally using a system-level objective. At inference time, each UE only needs its own CSI.
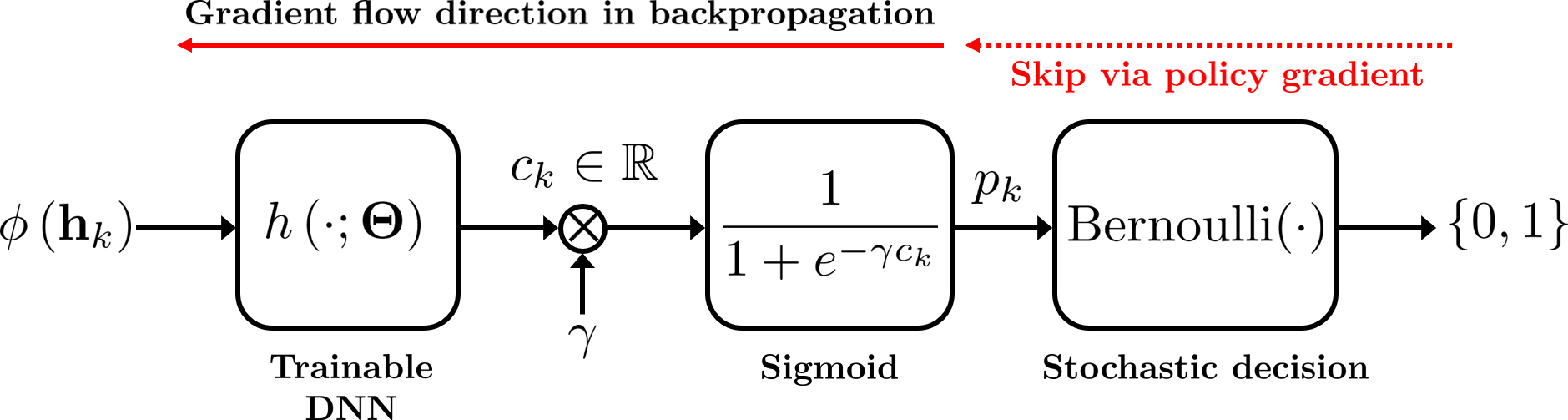
In the policy-gradient version, self-nomination is modeled as a Bernoulli policy, so training avoids direct differentiation through the hard decision and is easier to adapt across different scheduling rules.
Training
We study two training strategies.
The first is a direct optimization approach based on a primal-dual Lagrangian. Since both the binary feedback decision and the BS-side scheduling step are non-differentiable, this approach relies on gradient approximations.
Policy gradient
To avoid these heuristic gradient approximations, we also model self-nomination as a stochastic policy:
\[f(\mathbf{h}_k;\Theta) \sim \mathrm{Bernoulli}(p_k), \qquad p_k = \sigma(\gamma c_k).\]This turns the binary feedback decision into a sampled action. Instead of differentiating through the hard decision, we optimize the expected objective with respect to the policy:
\[J(\Theta) = \mathbb{E}_{a\sim \pi(\cdot \mid \{\mathbf{h}_k\};\Theta)} \left[\mathcal{L}(\{\mathbf{h}_k\}, a, \lambda)\right].\]Its gradient is computed using the log-derivative trick:
\[\nabla_{\Theta} \mathbb{E}_{\pi}\!\left[\mathcal{L}(\{\mathbf{h}_k\}, a)\right] = \mathbb{E}_{\pi} \!\left[ \nabla_{\Theta}\log \pi(a \mid \{\mathbf{h}_k\};\Theta)\, \mathcal{L}(\{\mathbf{h}_k\}, a) \right].\]A key advantage is that the gradient is isolated to the policy itself. In particular, the method does not require direct differentiation through the hard binary decision, and it is easier to apply across different scheduling policies without redesigning scheduler-specific gradient approximations. This makes the training procedure more modular and more broadly applicable.
During training, the stochastic policy explores different feedback decisions. In many cases, the learned probabilities move close to $0$ or $1$, so the resulting behavior becomes nearly deterministic at inference time.
Main result
In the UPA setting, self-nomination achieves strong MU-MIMO sum-rate while using far fewer feedback users. The key reason is that the channel is spatially dense, so reducing the candidate user set before BS-side scheduling can actually help by filtering out spatially incompatible users.
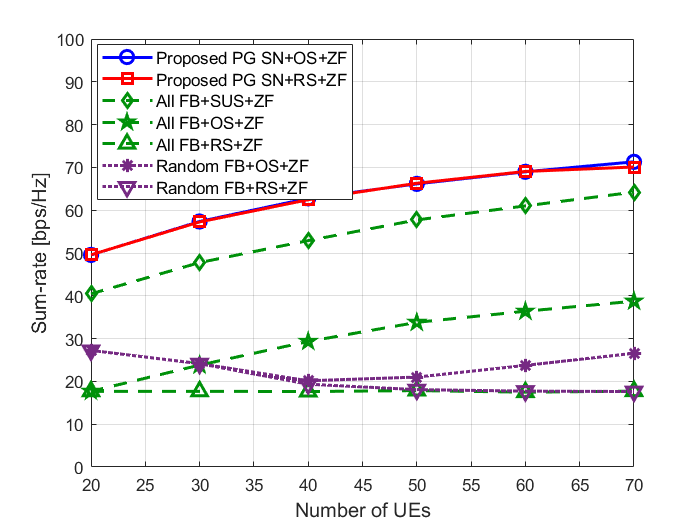
Self-nomination achieves strong MU-MIMO sum-rate performance as the number of UEs grows.
At larger user counts, this comes with roughly an 84% reduction in feedback users compared with full feedback, for example about 11 self-nominated users instead of 70 when the total number of UEs is 70. Even a simple RS-based pipeline remains very competitive once the feedback set is pruned in this way.
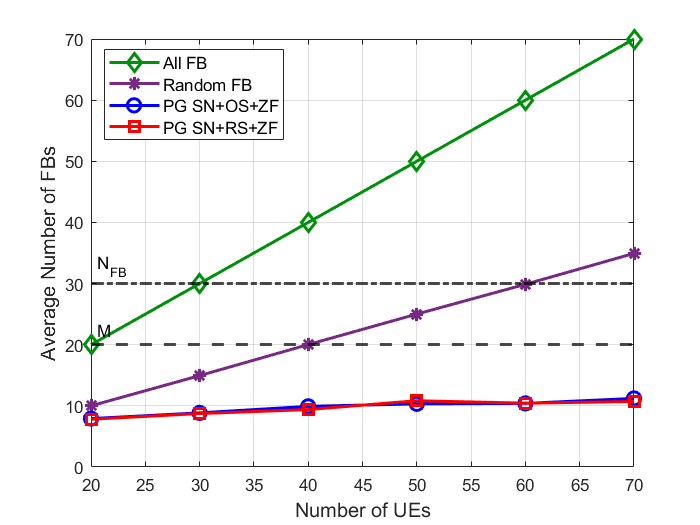
Self-nomination keeps the number of feedback users low while maintaining strong sum-rate performance.
Beyond simple thresholding
An important question is whether self-nomination is just learning a simple channel-gain threshold. The answer is no.
The fairness result below shows that self-nomination can keep performance close to the full-feedback case while using far fewer feedback transmissions.
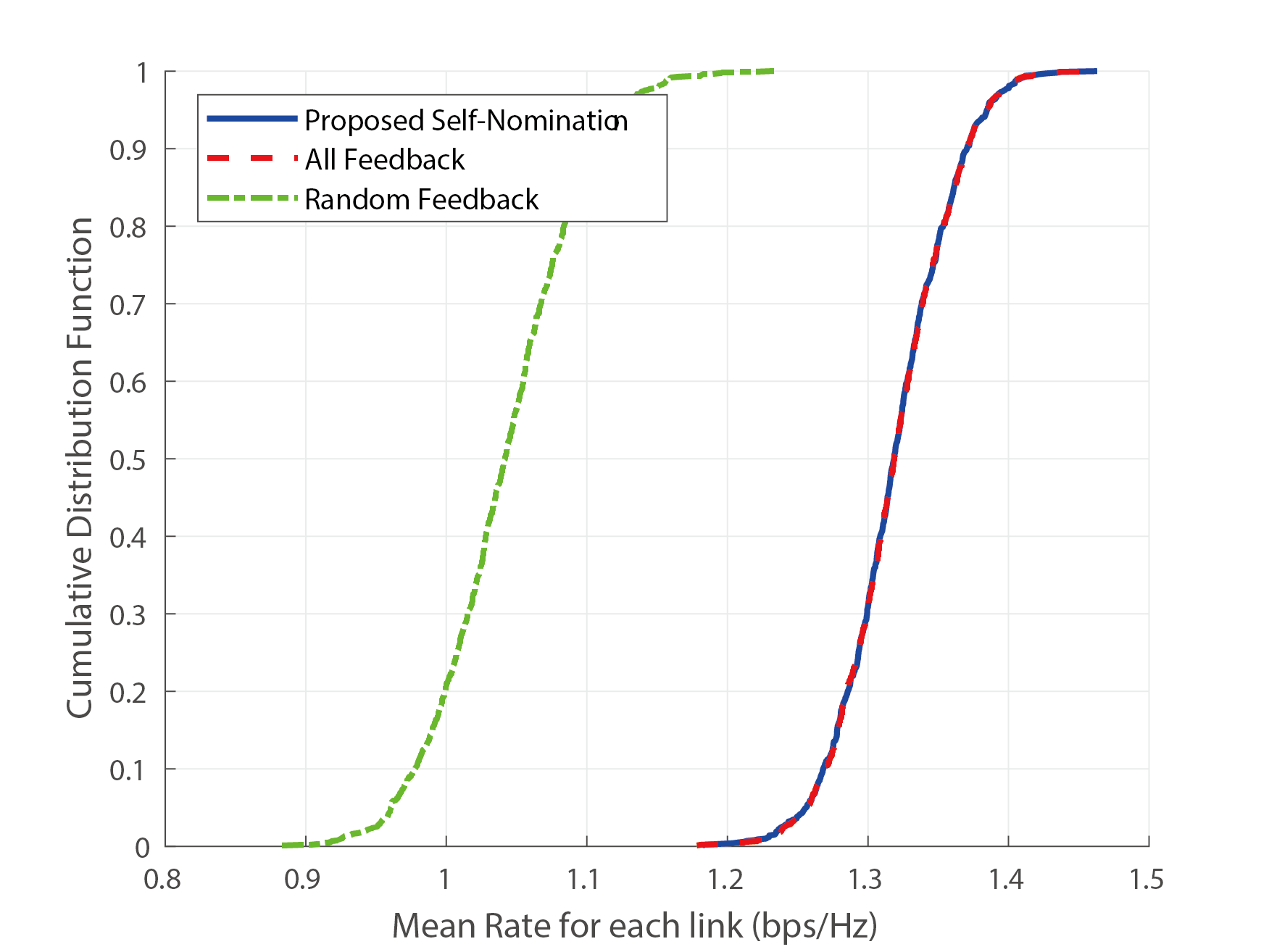
Under proportional-fair scheduling, self-nomination maintains fairness close to the full-feedback baseline with much lower feedback cost.
The next figure gives more insight into the decision rule itself. If the policy were using only a single global threshold, then the minimum channel gain required for nomination would look roughly similar across spatial groups. Instead, larger spatial clusters tend to require higher channel gain for nomination.
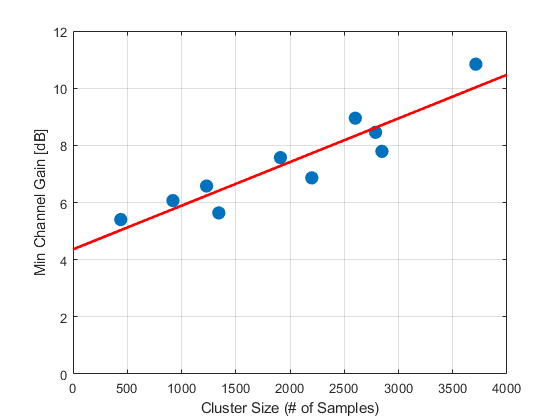
Users in larger spatial clusters tend to need higher channel gain to be nominated, showing that self-nomination adapts to spatial congestion rather than using a single fixed threshold.
This means the effective nomination rule depends on both power-domain and spatial-domain information. In that sense, self-nomination behaves more like a spatially adaptive soft threshold than a fixed CQI threshold.
Takeaway
The main message of this work is that, in MU-MIMO, CSI feedback should be selective rather than universal.
By letting each UE decide whether its CSI is worth feeding back, self-nomination reduces redundant uplink transmissions, simplifies BS-side scheduling, and can improve downlink performance by filtering out spatially incompatible users in advance. It also makes simple random scheduling surprisingly effective. At the UE side, users that do not feed back can remain silent, creating the potential for meaningful power savings.
Code
For implementation details and code, please see the project repository.
Paper
This post is based on the following paper: J. Park, F. Sohrabi, J. Du, and J. G. Andrews, “Self-Nomination: Deep Learning for Decentralized CSI Feedback Reduction in MU-MIMO Systems,” in IEEE Transactions on Wireless Communications, vol. 25, pp. 10321-10336, 2026.