End-to-End Deep Learning for TDD MIMO Systems in the 6G Upper Midbands
A short overview of our TWC 2025 paper, End-to-End Deep Learning for TDD MIMO Systems in the 6G Upper Midbands.
In conventional TDD MIMO systems, the BS first estimates or reconstructs the channel and then computes the downlink precoder. This pipeline is natural, but it may not be the most efficient one. If the final goal is downlink precoding, a more direct question is whether we can learn only the information that actually matters for transmission, rather than reconstructing the full channel first.
Core idea
For UE $k$, the received uplink pilot at the BS is
\[\mathbf{Y}_k^{\mathrm{ul}} = \mathbf{H}_k \mathbf{P}_k + \mathbf{N}_k^{\mathrm{ul}}.\]Instead of using a fixed pilot designed only for channel estimation, we let the UE generate a channel-adaptive pilot
\[\mathbf{P}_k = f_{\mathrm{UE}}(\mathbf{H}_k),\]and let the BS compute the downlink precoders directly from the received uplink pilots
\[[\mathbf{F}_1,\ldots,\mathbf{F}_K] = f_{\mathrm{BS}}(\mathbf{Y}_1^{\mathrm{ul}},\ldots,\mathbf{Y}_K^{\mathrm{ul}}).\]This turns uplink training into a task-oriented representation problem. The entire system is trained end-to-end to maximize the downlink sum-rate, rather than to minimize channel reconstruction error.
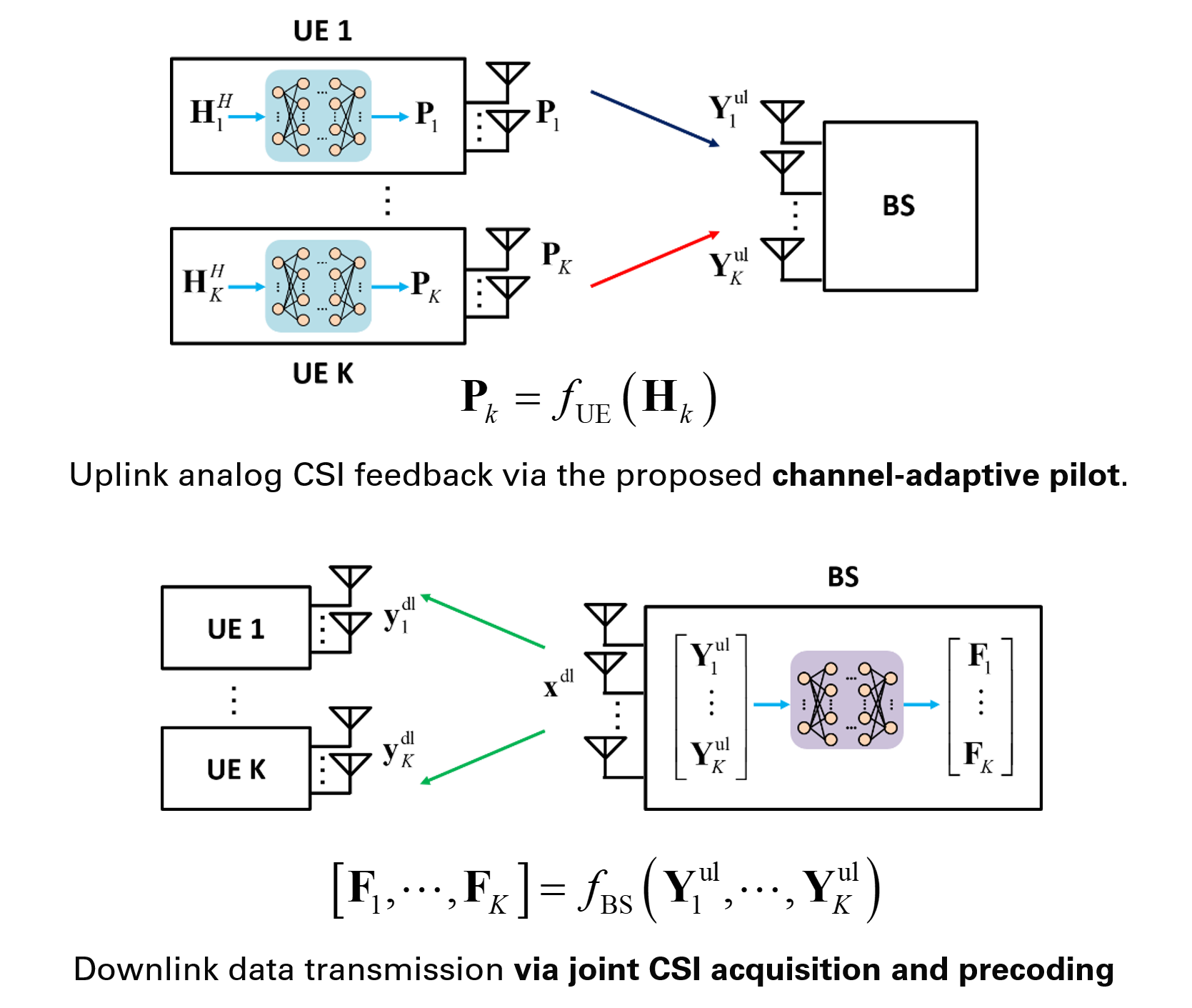 The proposed framework jointly learns UE-side channel-adaptive pilot generation and BS-side joint CSI acquisition and precoding.
The proposed framework jointly learns UE-side channel-adaptive pilot generation and BS-side joint CSI acquisition and precoding.
Why this matters
In a conventional design, pilot length is tied to full channel reconstruction. This increases uplink overhead and BS-side processing. In contrast, the proposed method only tries to preserve the information needed for precoding.
A convenient way to write the objective is
\[\max_{f_{\mathrm{UE}},\,f_{\mathrm{BS}}} \sum_{k=1}^{K} R_k,\]where $R_k$ denotes the achievable downlink rate of user $k$. The key point is that channel estimation is no longer treated as the end goal. Instead, CSI acquisition and precoding are learned jointly with respect to the communication metric of interest.
Why MU-MIMO needs more structure
For MU-MIMO, a naive DNN that directly maps pilots to precoders can work reasonably well at low SNR, but it becomes less reliable when inter-user interference plays a larger role. MU-MIMO precoding has strong underlying structure, especially when interference suppression is important.
To capture this, we use a theory-guided structure-based DNN motivated by the optimal linear MU-MIMO precoder. In simplified form, the target structure can be written as
\[\mathbf{F}_k = \gamma \left( \beta \mathbf{I} + \sum_{m=1}^{K} \mathbf{H}_m \mathbf{W}_m^H \mathbf{Q}_m \mathbf{W}_m \mathbf{H}_m^H \right)^{-1} \mathbf{H}_k \mathbf{W}_k^H \mathbf{Q}_k.\]The network does not explicitly compute this closed-form solution. Rather, this structure provides a useful inductive bias that helps the BS network learn interference-aware precoding more effectively.
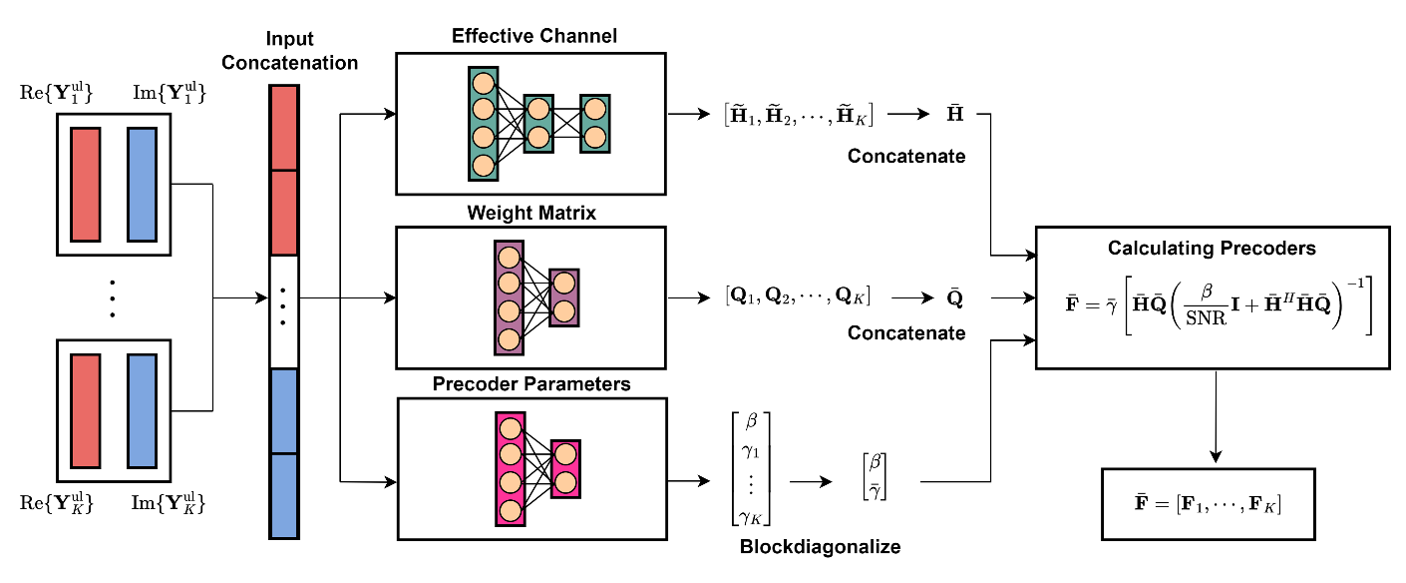 For MU-MIMO, the BS DNN is designed to reflect the structure of the optimal linear precoder instead of relying on a purely black-box mapping.
For MU-MIMO, the BS DNN is designed to reflect the structure of the optimal linear precoder instead of relying on a purely black-box mapping.
Interpreting the learned pilot
One useful interpretation is that the channel-adaptive pilot acts as a learned linear compression of the channel. More precisely, it learns a projection that preserves the channel structure most relevant to downlink precoding.
The figure below gives an angular-domain view of this idea. Compared with a conventional Walsh-code pilot, the learned pilot preserves the dominant channel structure more clearly, which helps the BS recover the information needed for effective downlink transmission.
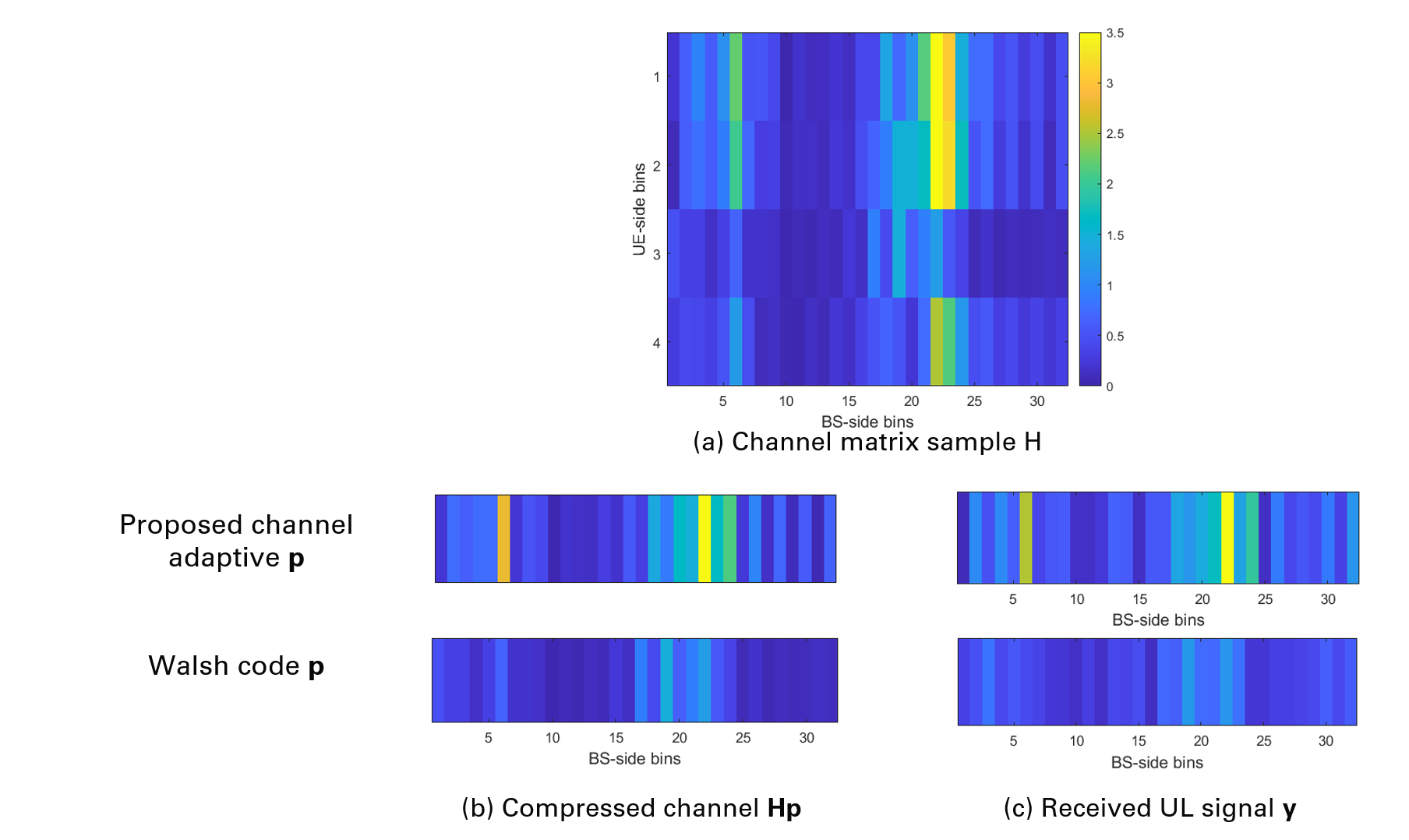 The learned pilot can be interpreted as a structured channel compression that preserves dominant angular-domain information more effectively than a conventional pilot.
The learned pilot can be interpreted as a structured channel compression that preserves dominant angular-domain information more effectively than a conventional pilot.
Main result
The main empirical takeaway is straightforward. The proposed method reduces pilot overhead and avoids explicit full-channel reconstruction, while still achieving strong downlink performance.
In MU-MIMO, the structure-based DNN consistently outperforms both the naive DNN and conventional estimation-based baselines. The gains become more pronounced when interference suppression is more critical, such as at moderate-to-high SNR or when the pilot length is limited.
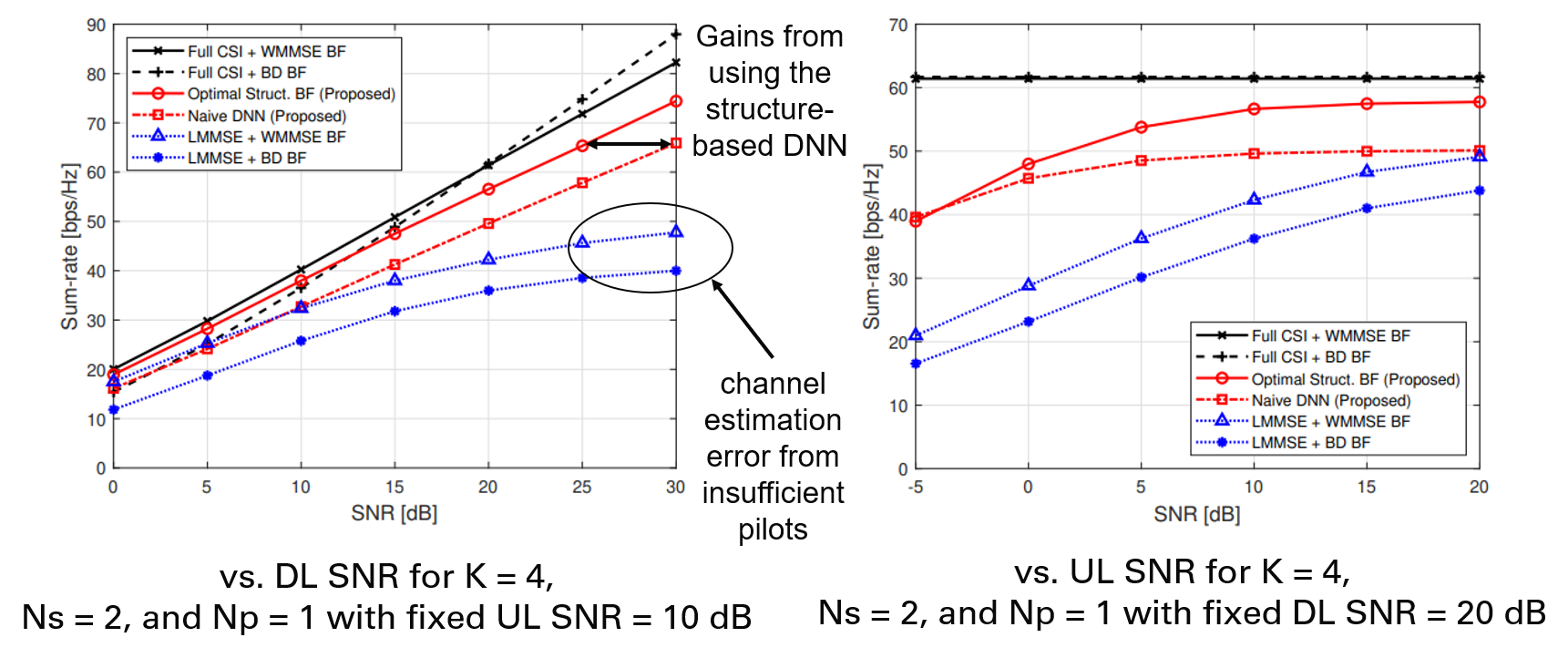 The structure-based DNN provides clear MU-MIMO sum-rate gains over the naive DNN and conventional LMMSE-based baselines.
The structure-based DNN provides clear MU-MIMO sum-rate gains over the naive DNN and conventional LMMSE-based baselines.
Takeaway
The main message of this work is that, in TDD MIMO, full channel reconstruction is not always the right intermediate target. If the ultimate goal is downlink precoding, it can be better to learn a channel-adaptive uplink representation and optimize the entire UE-to-BS pipeline directly for sum-rate.
This is especially important in MU-MIMO, where incorporating model-based structure into the BS DNN can substantially improve interference management compared with naive end-to-end designs.
Code
For implementation details and code, please see the project repository.
Paper
This post is based on the following paper: J. Park, F. Sohrabi, A. Ghosh and J. G. Andrews, “End-to-End Deep Learning for TDD MIMO Systems in the 6G Upper Midbands,” in IEEE Transactions on Wireless Communications, vol. 24, no. 3, pp. 2110-2125, March 2025.